
The 10 Immutable Laws of Context Engineering
Why 99% of AI projects fail at the prompt layer, and the architectural physics of the ones that win.

I watched a senior leader spend three weeks optimizing prompts for their AI coding assistant. Better phrasing. Clearer instructions. More examples. The results kept degrading.
The problem wasn’t the prompts. It was that they were solving the wrong problem entirely.
They were playing chess while the game had shifted to architecture.
Most organizations are making the same mistake. They are treating AI as a better autocomplete when it is actually a fundamentally different substrate that operates under its own physics. The prompt is 0.1% of what the model perceives. The other 99.9% is context—and most teams are architecting it by accident, not by design.
Context Engineering is the formal discipline of designing the complete informational environment in which AI operates. It is not prompt engineering’s evolution. It is its replacement.
In a world where models are commoditized and intelligence is abundant, your moat is not your model. It is your context.
Here are the ten immutable laws that separate organizations that scale AI from those that drown in it.
Law 1: Structure Your Knowledge for Machines, Not Meetings
What You’re Doing Now:
You’ve connected your AI to everything—Slack, Notion, Google Docs, your project management system. You’re feeding it raw meeting transcripts, strategy memos, PRDs, and slide decks. Yet, the AI still can’t answer basic questions about your product roadmap or tell you what was decided in last week’s leadership meeting.
Why It Fails:
Your AI isn’t reading those documents the way a human does. When you dump a 40-slide strategy deck into your system, the AI has to do expensive, real-time translation work—extracting decisions from discussions, filtering signal from noise, and compressing rambling context into something actionable. It is doing this work under severe constraints, without the structure it needs.
Raw documents are optimized for human consumption (narrative flow). AI needs machine-readable structure (relationship density).
The Law States:
Stop storing meeting transcripts and slide decks as your source of truth. Translate your organizational knowledge into structured formats first: decision logs, entity relationships, versioned facts.
When a strategy changes, don’t add another deck to the pile—update the structured record. Your AI should be able to query “what’s our Q1 priority” and hit a clean, structured answer, not search through 47 meeting notes hoping to infer it.
Implementation Note:
Move from storing Documents to storing Entities.
Bad Context: A 5-page PDF titled “Q1 Strategy Meeting Notes.pdf”
Good Context: A JSON-LD or Graph object:
JSON
{
“@type”: “StrategicDecision”,
“id”: “dec-2025-q1-focus”,
“decision”: “Pivot to Agentic Interface”,
“status”: “active”,
“valid_from”: “2025-01-01”,
“supersedes”: “dec-2024-q4-growth”,
“owners”: [”@michael”, “@bri”],
“evidence”: [”uri:meeting-notes-47”]
}The machine doesn’t need the meeting. It needs the decision.

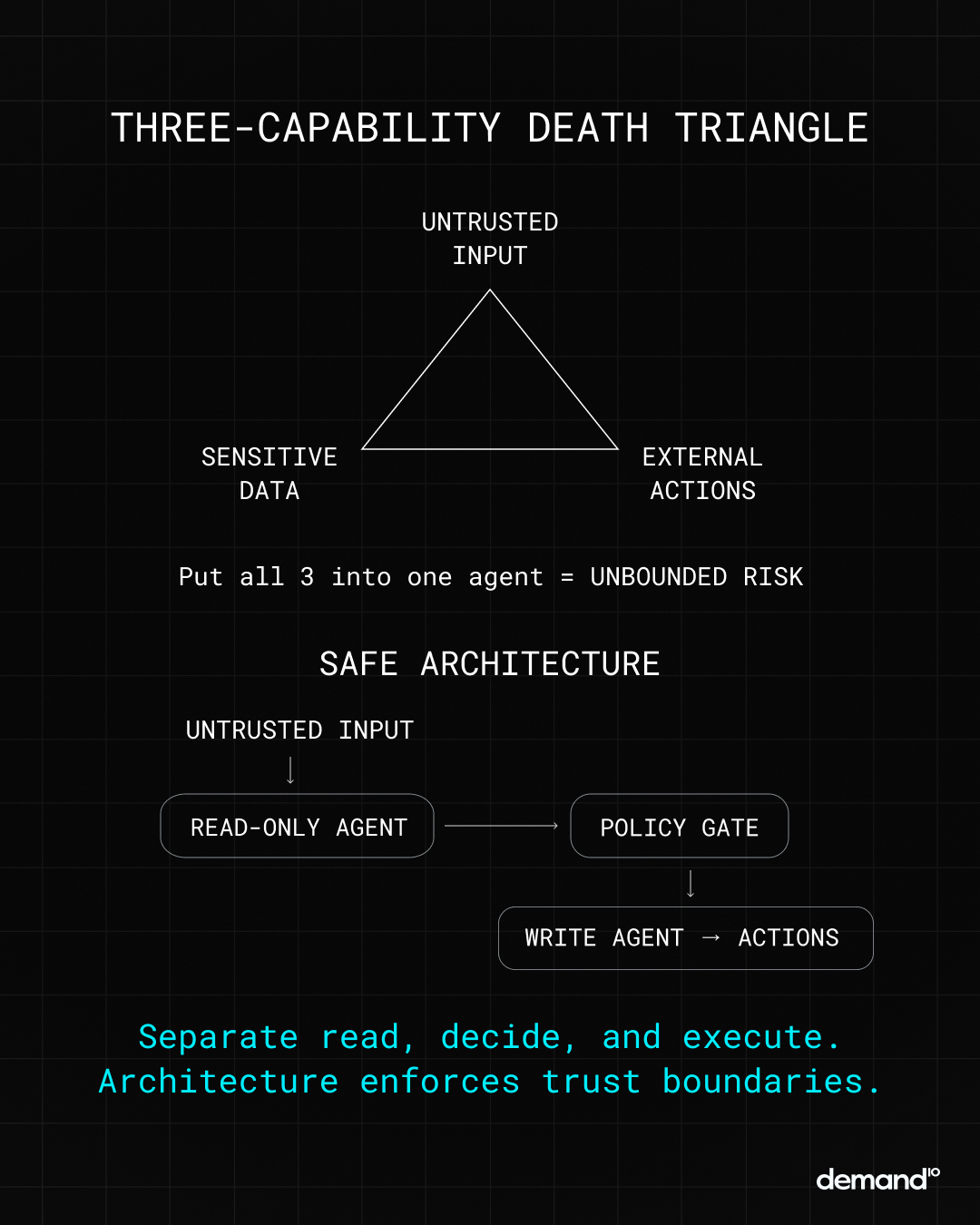
Law 2: Never Give AI Both Trust and Action in the Same System
What You’re Doing Now:
Your AI agent can read customer emails, access your database, and send responses or trigger workflows. You’ve added instructions: “Be careful,” “Always verify,” “Don’t do X.” Sometimes it works perfectly. Sometimes it makes catastrophic decisions that violate your policies in ways you never imagined.
Why It Fails:
Any system that simultaneously processes (A) untrusted inputs (emails, user queries), has access to (B) sensitive data (database, customer info), and can take (C) external actions (send emails, trigger workflows) has unbounded risk.
Instructions cannot constrain adversarial inputs. A clever prompt injection can route around your guardrails. You are trapped between making the system useful and making it safe.
The Law States:
You cannot secure this architecture with better prompts. You need structural separation. This is the Rule of Two: An agent may have any two of these capabilities, but never all three.
Insert a hard gate: either a human approval step for high-stakes actions, a cryptographic policy layer that hard-blocks certain operations, or an air gap between what the AI can read and what it can execute.
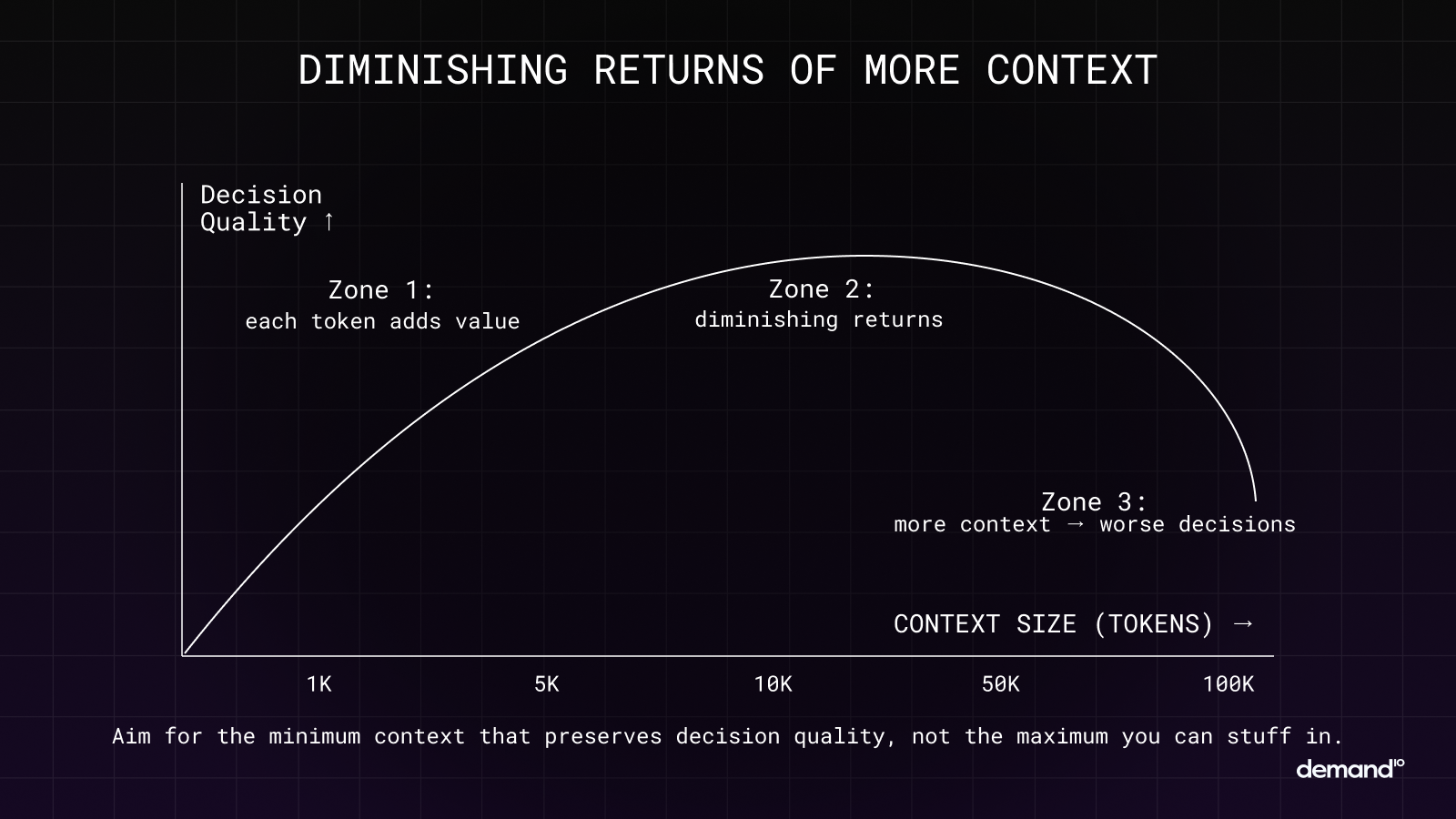
Law 3: More Context Destroys Performance
What You’re Doing Now:
You gave the AI everything. The full codebase. Every support ticket. Complete conversation history. Every document in the knowledge base. You figured more information means better answers. Instead, performance degraded. The AI started ignoring critical details you know it had access to. Responses became generic or wrong.
Why It Fails:
Information gain is submodular: each additional piece of context you add provides less value than the last. Past a certain threshold, adding more context makes the system worse.
This is due to Attention Dilution. In transformer architectures, the attention mechanism must distribute its probability mass across all tokens. As the context window ($N$) grows, the attention weight assigned to any single critical fact diminishes ($\propto 1/N$). The signal-to-noise ratio collapses.
The Law States:
Your job is not to give the AI everything. It is to give it the minimum necessary information that preserves decision quality. Be ruthlessly selective. Prioritize recent, relevant, high-confidence information. Remove redundancy. Compress aggressively.
Law 4: Speed is a Memory Problem, Not a Model Problem
What You’re Doing Now:
You upgraded to the fastest models. You’re running on H100s. You’re paying for premium tiers. Your AI is still slow. Time-to-first-response is killing the user experience. Long conversations make everything worse. You assume you need even more compute power.
Why It Fails:
Your bottleneck isn’t how fast the model can think (Compute). It’s how fast it can access its memory (Bandwidth).
During the generation phase (decoding), the GPU is memory-bandwidth bound, not compute bound. For every token generated, the entire KV Cache (the model’s “memory” of the conversation so far) must be moved from HBM (High Bandwidth Memory) to the compute units.

If you double your context size, you are doubling the data that must be moved for every single word the AI generates.
The Law States:
Throwing more compute at the problem fails. The constraint is physical—the speed of light across the memory bus. If you want speed, optimize your context architecture: minimize the context size sent to the model. Use caching (like prompt caching) to avoid re-computing the invariant parts of your context. Less context, better structured, is faster than more context on better hardware.
Law 5: Outdated Context is Worse Than No Context
What You’re Doing Now:
Your AI keeps giving answers that were correct last month but are wrong now. It references deprecated features, outdated pricing, old team structures, or strategies that changed. You refresh the data periodically, but the problem keeps coming back. The AI isn’t making things up—it’s confidently wrong in weirdly specific ways.
Why It Fails:
Context decays over time. Facts that were true yesterday become false today. Your AI has no internal clock. It cannot tell the difference between fresh information and stale information unless you explicitly tell it.
When it reasons from outdated context, it is not hallucinating—it is being logical with bad inputs.
The Law States:
Context is not a static asset. It requires Bitemporal Modeling. You must track two time dimensions for every piece of knowledge:
Valid Time: The real-world time period during which the fact is true.
Transaction Time: The time the fact was entered into the system.
When something changes—a strategy pivot, a feature sunset—don’t just add the new information. You must explicitly invalidate the old by closing its valid_to timestamp. Stale context is worse than missing context because it creates systematic misinformation.
Law 6: Where You Put Information Matters as Much as What You Provide
What You’re Doing Now:
You included all the critical information in your prompt. You verified it’s there. The AI completely ignored it and gave you a generic answer. Frustrated, you moved the same information to the beginning of your prompt—and suddenly it worked perfectly.
Why It Fails:
The AI’s context window is not a flat list where everything has equal weight. It is a U-shaped curve. Information at the very beginning (primacy) and very end (recency) gets the most attention. Information buried in the middle effectively becomes invisible.
This is the “Lost in the Middle” phenomenon (Liu et al., 2023). It is an emergent property of how attention heads allocate focus over long sequences.
The Law States:
Context architecture is a spatial design problem. Design your prompts and knowledge structures with positional awareness.
Crucial Instructions: Place at the very Start.
Critical Data: Place at the very End (closest to the generation point).
Supporting Context: Place in the Middle.
Don’t dump information randomly. Architect the topology of your prompt.

Law 7: No Amount of Prompting Can Fix Missing Information
What You’re Doing Now:
You keep rewriting prompts, hoping the AI will “figure out” what you need. You try different phrasings. You add “think step by step” or “be thorough” or “consider all angles.” Sometimes it works. Usually it doesn’t. You are stuck in an endless loop of prompt tweaking.
Why It Fails:
Information Cannot Be Created. Per the Data Processing Inequality, post-processing (prompting) cannot increase the information content of the source (context). If the signal $X$ is not in the context $C$, the model cannot recover it.
When you say “think carefully,” you are not giving it new data. You are asking it to do more compute on the same insufficient inputs.
The Law States:
Stop trying to prompt your way out of a data problem. Your job is to ensure the information required to solve the task actually exists in the context before the prompt runs. If the AI doesn’t know something, either add that knowledge to the context or accept that it cannot answer. Prompt engineering cannot compensate for missing information.
Law 8: Your Moat is Context, Not Models
What You’re Doing Now:
You’re worried competitors will copy your AI features. You’re trying to differentiate on which model you use or what prompts you write. You’re keeping your prompt library secret. Everything still feels easily replicable.
Why It Fails:
Models are commoditizing. Within months, competitors have access to the same capabilities (GPT-5, Gemini 2.0). Prompts are trivial to reverse-engineer. If your competitive advantage is “we use GPT-4” or “we have really good prompts,” you have no moat.
The durable asset is not the model. It is your Living Context Portfolio—the structured knowledge, the curated relationships, and the institutional memory you’ve built over time.
The Law States:
Invest in Recontextualization Debt (RCD). RCD is the cost a competitor would pay to rebuild the entire operating state of your system (user history, preferences, integrations, knowledge graph) from scratch. The harder it is to recreate your context, the deeper your moat.
Law 9: Stop Optimizing Prompts, Start Building Systems
What You’re Doing Now:
Every new use case requires a new prompt. Your team has written thousands of them. There is no consistency. Every AI interaction feels like starting from scratch. Different teams use different approaches. Nothing transfers. You are drowning in unmaintainable prompt spaghetti.
Why It Fails:
You are treating symptoms, not causes. A prompt is a one-time instruction. It is a tactic. What you actually need is a Context Engine—a piece of middleware that sits between your data and the model.
The Law States:
The shift from prompt engineering to context engineering is the shift from tactics to strategy. Stop writing one-off prompts. Architect a pipeline:
Ingestion: Raw Data $\rightarrow$ Structured Knowledge Graph
Retrieval: Query Intent $\rightarrow$ Graph Traversal + Vector Search
Assembly: Retrieved Nodes $\rightarrow$ Optimal Context Window
Generation: Context $\rightarrow$ Model Response
Build the machine that builds the prompt.

Law 10: You Don’t Have an AI Problem, You Have an Operating System Problem
What You’re Doing Now:
Endless alignment meetings. Decks created just to sync context. Slack threads to find what was decided three weeks ago. Every new hire takes months to ramp because institutional knowledge lives in people’s heads. Every project reinvents the wheel. Now you’ve added AI to this mess, and it’s making everything worse—you’re spending time explaining your broken processes to machines.
Why It Fails:
Your organization is already a context distribution system. Information flows (or doesn’t) between people according to the architecture you’ve built—usually by accident, not design. Most companies run on Corporate Drag: bureaucratic friction, meeting sprawl, and misalignment.
AI doesn’t fix broken systems. It amplifies them. If your context is trapped in Slack threads and meeting notes, your AI will be as confused as your newest hire.
The Law States:
You don’t need better AI. You need a better organizational context system. This is an architectural problem, not a tools problem. Build a shared context layer—a single source of truth that both humans and AI can read from and write to. Make decisions, strategies, and institutional knowledge queryable, not buried.
The companies that win won’t have better models. They will have better context operating systems.
The Diagnostic
Most organizations are trying to add AI to their existing systems. They are treating it as a better intern, a faster search engine, a smarter autocomplete.
But AI doesn’t augment broken systems. It amplifies them.
If your context architecture is ad-hoc, your AI will be unpredictable. If your knowledge is siloed, your AI will be inconsistent. If your institutional memory is lost in Slack threads and meeting notes, your AI will hallucinate.
Here is the diagnostic question: When was the last time a critical decision was made in your organization, and everyone—human and AI—had access to the same, verified, current context to make it?
If the answer is “never,” you don’t have a prompting problem. You have an operating system problem.
And that is exactly what Context Engineering solves.
Michael Quoc is the founder and CEO of Demand.io. He writes about building AI-native companies from first principles.
This article comes at the perfect time, resonating deeply with the architectural context shift, though initial human-centric data ingestion design remains cruciaal.
You nailed the critical failure mode. Most RAG systems flatten time - they can't distinguish between what was true and what is true. That bitemporality gap is where "hallucination" usually hides. And agreed on Law 4. We keep trying to solve a physics problem (memory bandwidth) by throwing more compute at it. It doesn’t work.