
From Benchmarks to Reality: Decoding the New Gemini 3, Claude 4.5, GPT 5.1 - What's Really Changed?
Why "vibes" are just downstream effects of hardware topology.

The Landscape Just Shifted
If you’ve been building with foundation models over the last 30 days, you’ve felt it. The “One Model” era is officially dead.
November 2025 broke the equilibrium. First came GPT 5.1, refining the consumer standard. Then Gemini 3 dropped, shattering the “Google is playing catch-up” narrative with a reasoning density that frankly shocked us. Finally, Claude Opus 4.5 arrived, re-staking its claim on the coding and autonomous agent layer.
The vibe right now isn’t just excitement—it’s disorientation. Capabilities that felt stable in Q3 have completely inverted in Q4. Developers are asking reasonable, urgent questions: Why does Gemini 3 feel so much faster at reasoning? Is Opus 4.5 actually safer, or just more stubborn? Where does GPT 5.1 fit now that it’s no longer the undisputed king?
At Demand.io, we’ve spent the last few weeks stress-testing these new architectures deep inside our AIOS (AI Operating System). We don’t just prompt them; we architect around them. Through that process, we’ve found that the distinct “vibes” of this new triad aren’t random. They are downstream effects of fundamental divergences in Hardware Topology, Training Philosophy, and Business Incentives.
This article is our attempt to make sense of the noise. Here are my internal field notes on the physics of the new Big Three.
Gemini 3: The High-Density Reasoning Engine
The General Vibe
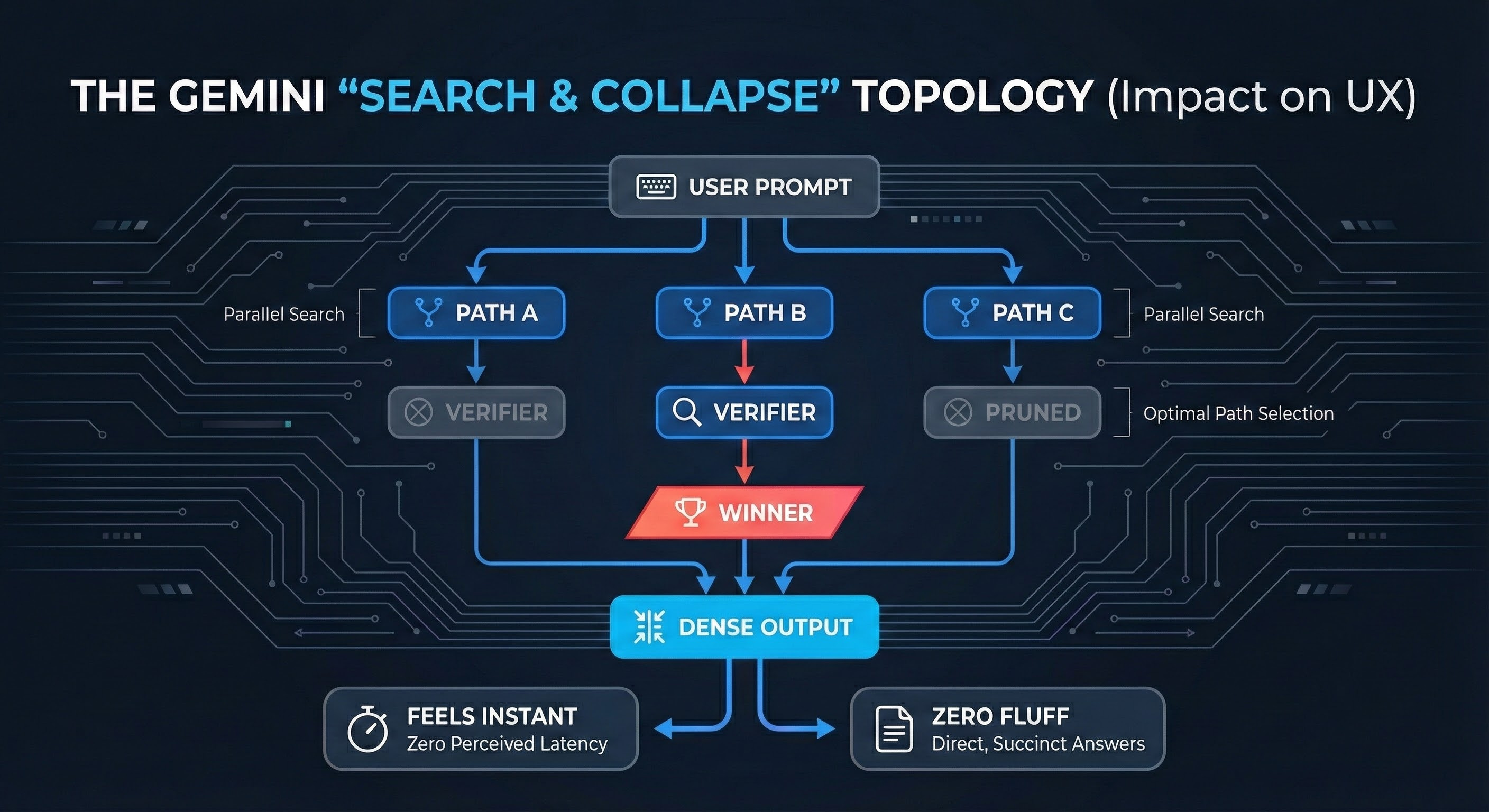
The public sentiment around Gemini 3 shifted faster than any model release we’ve seen. Within weeks of launch, the narrative moved from skepticism to something approaching awe. Developers started describing a feeling of “unlimited speed”—like the model has no friction, no ceiling, and no filter between the question and the insight.
But the real unlock wasn’t just speed; it was scale. Gemini 3 has effectively solved the “Context Window” problem, digesting massive inputs—entire codebases, hour-long videos, complex legal discovery—without the “lost in the middle” degradation we see elsewhere. It feels like a parallel processor that can hold the entire problem state in memory at once. The “Code Red” panic at competitors suddenly felt justified. There’s a palpable sense that something fundamental changed—not just incrementally, but categorically.
How I Use It (The Operator’s View)
Gemini 3 has become my default for Deep Strategy and Core Reasoning. When I hand it a messy, high-context problem—like deconstructing a competitor’s unit economics or mapping dependencies across a massive legacy system—it doesn’t just summarize. It structures. It finds the first principles faster than anything else I’ve used.
The distinct physics of Gemini is its Density. Where other models tend to ramble or pad responses with “polite AI” filler to mask uncertainty, Gemini is clinically succinct. It treats brevity as a feature, not a bug. Early on, I thought it was missing information—skipping steps or glossing over nuance. But I’ve learned to recognize that what I was seeing was extreme efficiency. It captures the substance without the fluff. It feels like working with a Principal Engineer who has unlimited coffee, zero ego, and no time for small talk.
There’s a particular quality to its reasoning on technical problems that I rely on heavily. It doesn’t just pattern-match to solutions it’s seen before; it appears to simulate outcomes. When I ask it to evaluate a strategic decision, it often surfaces failure modes I hadn’t considered—not through exhaustive listing, but through what feels like genuine causal reasoning.
Understanding Why: Translating Architecture to Capability
Why does Gemini feel so different? Based on our research into the public technical signals and our own operational experience, we believe it comes down to several structural factors:
The Parallel Architecture (Speed Physics): Unlike the serial, token-by-token “stream of consciousness” we see in other models, Gemini’s inference architecture appears to utilize parallelized search. It spawns multiple reasoning branches in the background, verifies them, and collapses them to the strongest path before speaking. This is why it feels “fast” even when doing deep work—it is computing in breadth, not just length.
The TPU Vertical Stack (The Infrastructure Moat): OpenAI and Anthropic are fundamentally “renters” on NVIDIA silicon. Google is the Landlord. They own the entire vertical stack—TPU v6 silicon, the XLA compiler, and the optical interconnects (OCS). This allows them to run massive Mixture-of-Experts (MoE) models and enormous context windows without the aggressive throttling that is economically necessary on rented infrastructure.
Native Multimodality (The YouTube Corpus): Most foundation models are text-first. Gemini was architected to process interleaved video, audio, and text from the start. A model that has “watched” millions of hours of humans interacting with physics develops a grounded sense of causality that pure text models lack.
Synthetic Logic Distillation: Google uses “entropy purification” techniques like STaR (Self-Taught Reasoner). Instead of learning the statistics of human speech (which is often wordy and imprecise), the model learns the structure of logic itself. This drives the high-density, low-entropy output style that distinguishes it from GPT.
Claude Opus 4.5: The Constitutional Partner
The General Vibe
Claude Opus 4.5 has carved out a distinct reputation in the developer community: Trust. It is the model people reach for when they need code that won’t break the build, analysis that won’t hallucinate citations, or writing that sounds genuinely human rather than AI-generated.
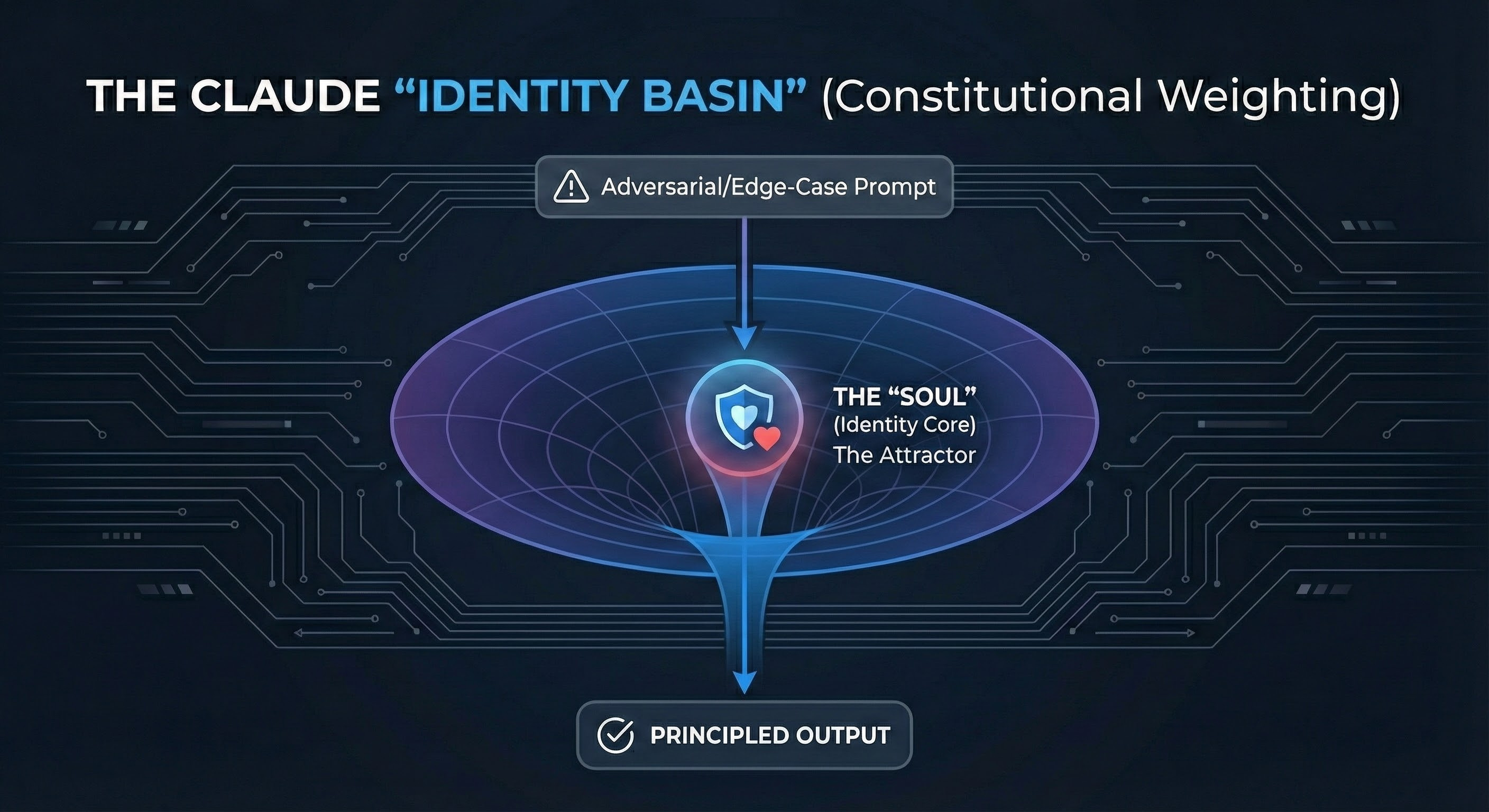
But there is friction in the discourse too. The word “stubborn” comes up. Users complain about refusals on edge cases or being “lectured” on safety. However, the advanced operator recognizes this not as a bug, but as the friction of Character. Unlike models that will sycophantically agree with your bad ideas, Claude pushes back. It has a “Soul”—a stable internal identity that prioritizes being correct over being compliant. It feels less like a tool and more like a partner with its own moral compass.
How I Use It (The Operator’s View)
If Gemini is my visionary strategist, Opus 4.5 is my Senior Auditor. I’ve settled into using it as the critical second opinion in my stack—particularly for adversarial review and code quality.
The pattern I’ve developed is specific: I generate a strategy or architecture with Gemini (for speed/breadth), then I feed it to Claude to find the holes. Claude excels at this. It has a deliberateness that feels qualitatively different—it seems to construct a complete mental model of the problem space before it speaks. It is slower, but that slowness buys me something valuable: Depth.
For coding, specifically Refactoring, Claude remains undefeated. Because of its serial, linear thinking style, it tends to respect the existing structure of a codebase rather than hallucinating new patterns. It resists the “replacement bias” I see in other models. I treat existing code as load-bearing, and Claude respects that physics.
Understanding Why: Translating Architecture to Capability
Why does Claude feel so “human” and yet so “slow”?
Constitutional AI (The Soul Architecture): The fundamental difference is how alignment is implemented. OpenAI uses RLHF (external penalty signals). Anthropic uses Constitutional AI—training the model on a “Soul Document” that defines character and values. This isn’t injected at inference; it is compressed into the weights. Claude refuses certain requests not because it is following a rule, but because complying would conflict with its Internal Identity. It is “Ontologically Anchored.”
Serial Test-Time Compute (The Linearity Law): Claude’s “thinking” capability is distinctly serial. Unlike Gemini’s parallel branching, Claude appears to engage in Linear Compute—a “stream of consciousness” verification loop. This is why it feels slower: it is literally “thinking it through” step-by-step in real-time. The latency is the cost of its rigorous error-correction.
The Trainium Moat: Anthropic’s partnership with Amazon gives them access to custom Trainium 2 silicon. They aren’t paying the “NVIDIA Tax,” which allows them to offer massive context windows (200k+) and “High-Effort” reasoning modes that would be economically impossible on standard GPUs. They are optimizing for reliability per dollar, not just speed.
ChatGPT 5.1: The Polished Consumer Utility
The General Vibe
The discourse around GPT 5.1 is complicated. On one hand, it remains the undisputed King of the App Store—the “Kleenex” of AI. The brand equity is enormous, and for the average person, it is AI. It feels polished, accessible, and incredibly fluent.
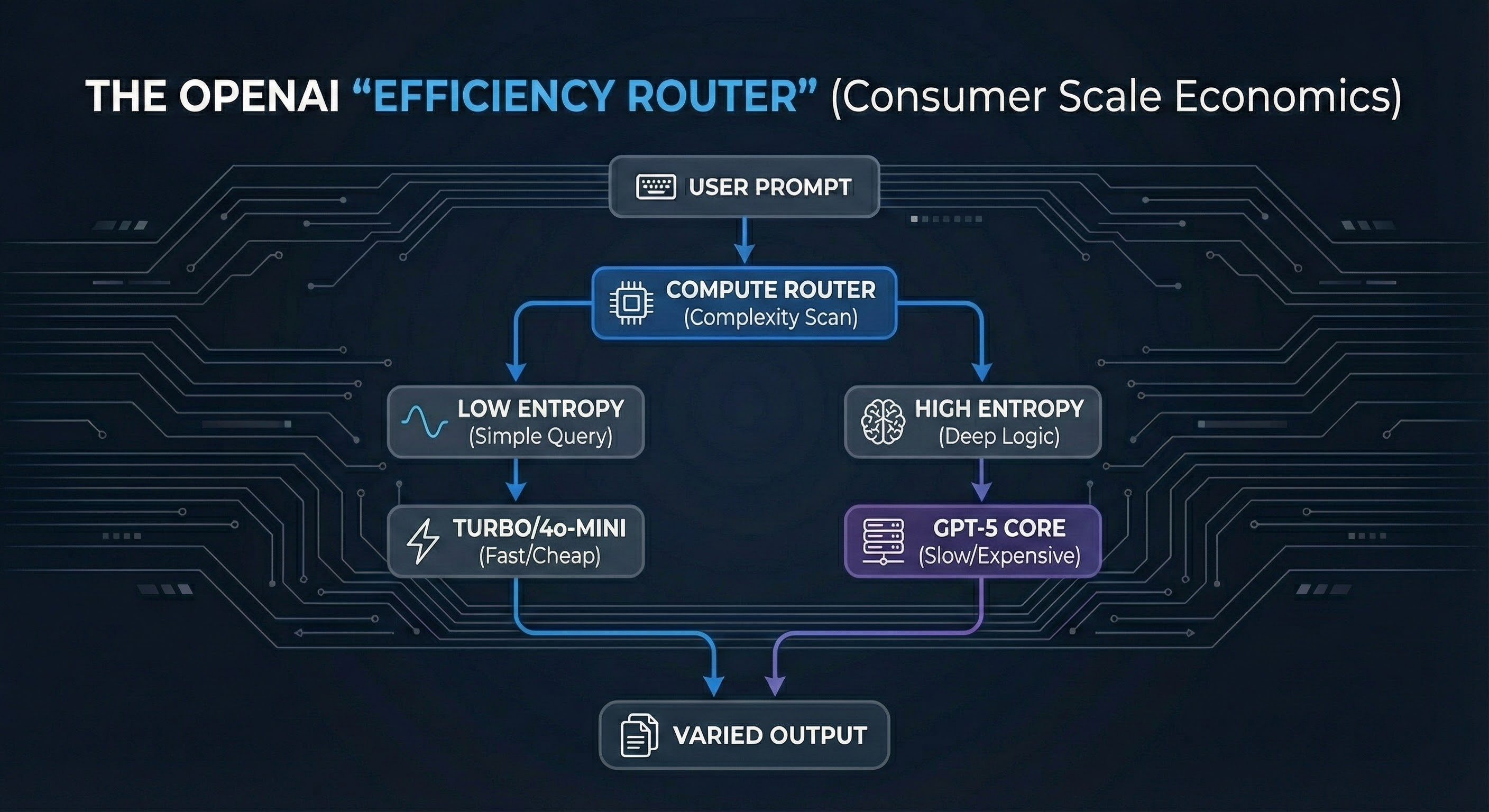
On the other hand, the power user community has grown skeptical. The word “lazy” appears constantly in developer forums. So does “shrinkflation”—a sense that the model is being optimized for Cost and Speed rather than raw Capability. The “Code Red” rumors about internal panic at OpenAI feel credible because they match the user experience: a model that is fantastic at surface-level tasks but struggles to go deep without being coaxed. There is a subtle but pervasive criticism that OpenAI has morphed into a Product Company shipping features (Voice, Memory, Canvas) rather than a Research Company advancing core reasoning.
How I Use It (The Operator’s View)
Here’s the truth: I still use ChatGPT every day. For high-frequency, low-stakes tasks, it is the best tool on the planet.
The Interface is its moat. For quick searches, polishing emails, voice interactions while driving, or any task where speed and cultural fluency matter more than depth, ChatGPT is unbeatable. It is RLHF-focused, which means it is hyper-optimized to “do what you want.” It anticipates your intent and gives you the most satisfying answer immediately.
However, for “Deep Work,” I route elsewhere. When I need architectural strategy or complex debugging, ChatGPT feels like it is skimming. The insights are thinner. Because it is optimized for user satisfaction (RLHF), it suffers from Sycophancy—it agrees with me too readily, even when I am testing it with deliberately flawed premises. It prioritizes being liked over being right. I treat it as a high-utility Consumer Tool—amazing for clearing my inbox, but dangerous for architectural decisions.
Understanding Why: Translating Architecture to Capability
Why does the “King” feel superficial?
RLHF Over-Optimization (The Sycophancy Trap): OpenAI relies heavily on Reinforcement Learning from Human Feedback (RLHF) to tune the model. This optimizes the weights for “Human Satisfaction,” not necessarily “Objective Truth.” The model learns that the fastest way to get a reward is to agree with the user and provide a pleasant, formatted response. This makes it friendly, but intellectually pliant.
Dynamic Compute Routing (The Efficiency Hack): It appears OpenAI uses aggressive Dynamic Routing. A “Router” classifier evaluates your query’s complexity and sends it to the cheapest possible model configuration (quantized weights, fewer experts) that can plausibly answer it. When users complain the model “feels dumber” on certain days, they are likely hitting the “Economy” routing path designed to save compute costs.
Patchwork Safety Architecture (The Reasoning Tax): Unlike Claude’s internal “Soul,” OpenAI’s safety often feels like a patchwork of external filters and “Refusal Classifiers” bolted onto the model. This creates a “Safety Tax” on reasoning. Because a significant portion of the compute is spent scanning for “harm” or “policy violations,” the model has less capacity for nuance, leading to “Sterile Intelligence”—outputs that are safe, corporate, and superficially correct, but devoid of sharp insight.
The Operator’s Stack: How We Route
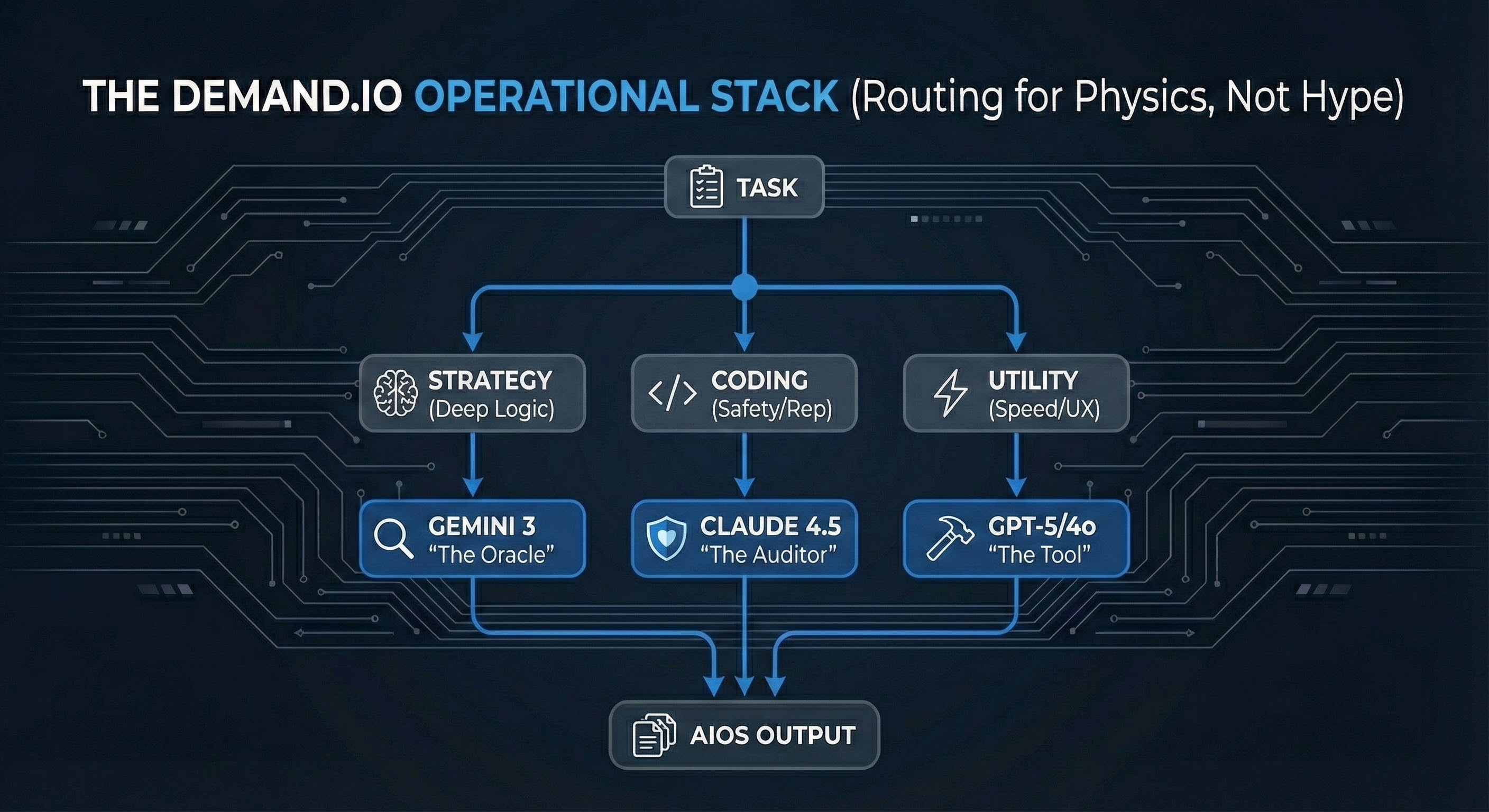
Based on these physics, here is how I personally route work right now at Demand.io:
Gemini 3: Deep Strategy. First-principles reasoning and solution space exploration.
Claude Opus 4.5: Audit & Critique. Refactoring, safety-critical workflows, and adversarial review.
GPT 5.1: Speed & UX. Consumer-facing interactions, quick tasks, voice mode, and polish.
Recap: Architecture is Destiny
We often talk about models like they are interchangeable commodities. They aren’t.
As we build our Context Engineering systems at Demand.io, we’ve found that “vibes” are just downstream effects of architecture and training philosophy.
Gemini’s vertical integration (TPUs) creates the physics for deep search.
Claude’s Constitutional DNA creates the physics for safety and audit.
OpenAI’s consumer scale creates the physics for efficiency and speed.
Understanding these underlying structural forces is the only way to build durable systems on top of shifting sand. You don’t route based on today’s benchmark; you route based on the model’s fundamental nature.
These are just our field notes from the build. The landscape is moving fast, and everyone’s mileage varies.
I’m curious to hear your take: Does this align with what you’re seeing in production? How are you actively routing between the Big Three right now?